
Compare PDF: 10 insider tips how to get the best results
You are asking yourself: “How can I compare PDF files?” That is a good question!
We are asked this question every day. And we have successfully answered it countless times.
The answer can be very simple. But unfortunately many instructions make it too easy here. Like here:
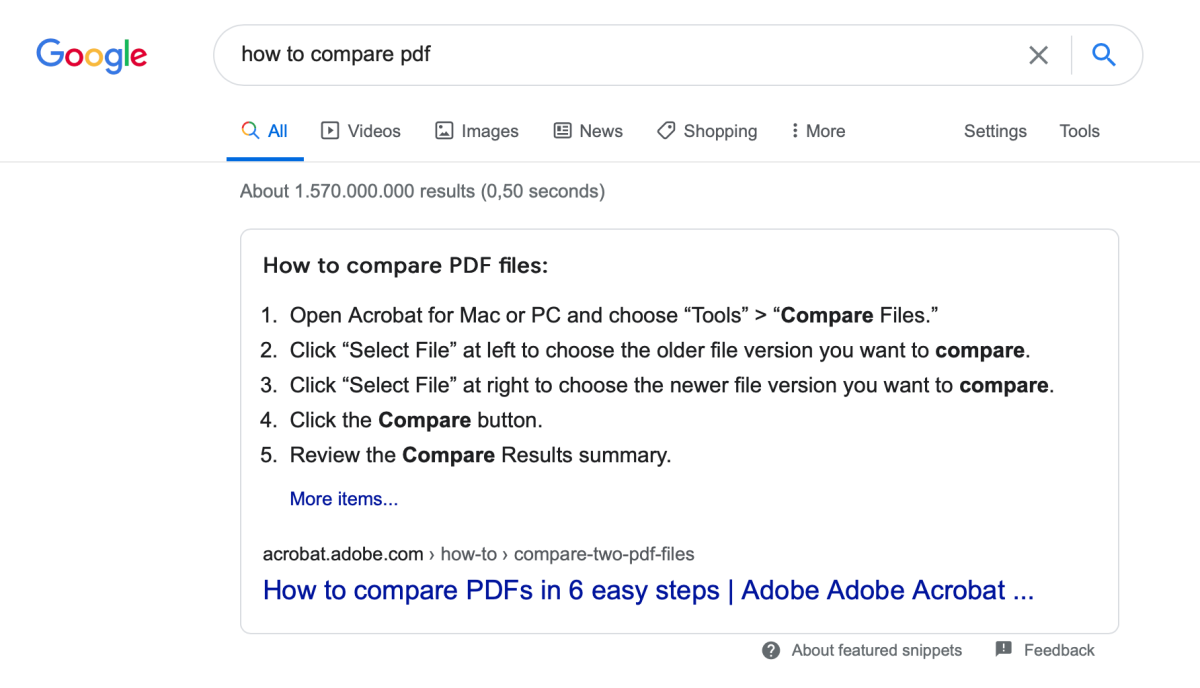
The advice to simply compare PDFs online is also common:
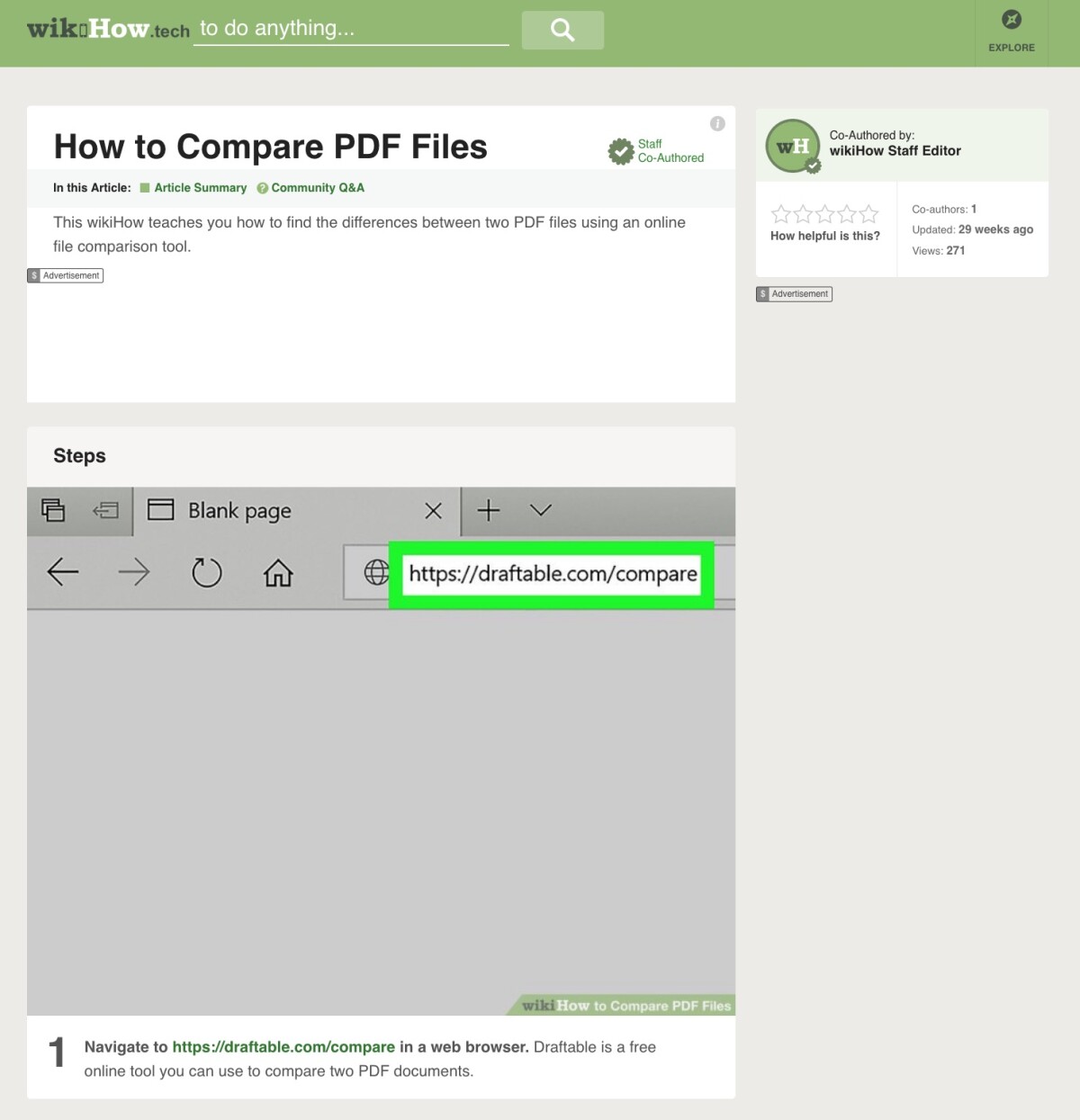
Well, these types of instructions are only half the story. To all readers who are satisfied with this and are now leaving our site, we wish a good trip…
Nice, you are still there! Then read on to become a ninja master in the art of PDF comparison. Let the others become masters of disaster.
Here we go:
- Basics:
- Inputs:
- Outputs:
- Workflow:
Tip 1: Make sure you set your focus: graphics or text!
Sure, you want to compare PDF documents. What even Google won’t tell you: PDF is not just PDF!
PDF is a complex container format, in which all kinds of file formats can be packed. Fortunately, you don’t need to go through the entire PDF spec now.
What you absolutely need to know about PDF documents is the following:
The main content types in a PDF are:

In order to be able to compare PDF files optimally, it is essential that you focus on one of the two content types text or graphics.
“But I have both! Why should I choose one?” There is a very logical reason for this:
The entirety of all PDF comparison tools on the market can be divided into one of two classes1:
- 1) Text-based PDF comparison
-
First, the text is extracted from the PDF documents. Then, a digital text comparison is performed. Differences are displayed as words or letters.
- 2) Graphical PDF comparison
-
The two documents are first converted into pixel images by means of a PDF renderer. Then, a digital image comparison is performed. Differences are highlighted as pixels or groups of pixels. Text and vector drawings are also compared on a pixel-by-pixel basis as part of the overall image.
This classification is important. It always applies, even if there are some tools which you can toggle between graphics and text comparison with a kind of mode switch. In principle, you then only have two completely different tools that are started under the same app name.
You will find more details on how both approaches work (soon) in a separate howto article: The great duel: text-based versus graphical PDF comparison!
How do you choose the right comparison tool?
There are two simple exclusion criteria for this:
![]()
How stable is the layout between the two documents?
If the layout is very different between your documents, for example by:
- changed fonts
-
e.g. Courier vs. Times New Roman or 10pt vs. 12pt
- changed line breaks
-
e.g. line widths changed or lines reformatted through larger text insertions / deletions
- changed column breaks
-
e.g. single column vs. multi-column text
- changed page breaks
-
e.g. PDF A has 5 pages, PDF B has 7 pages
then you cannot use a graphical comparison.
You then have to use a text comparison.
![]()
Does the relevant content of your PDF document consist of text at all?
A text-based PDF comparison can only work if you have searchable text in both PDFs.
If, on the other hand, the relevant text is available
- as pixel graphics
-
e.g. through scans or the output of a RIP
- as vector graphics
-
e.g. by converting fonts into paths or by an unfavorable PDF export (as with a PDF printer)
then you cannot initially use a text comparison.2
Likewise, if you need to see all the differences in graphic elements, a text comparison will not help you.
You then need to use a graphical comparison.
Tip 2: Online or offline, what is the right choice for you?
Comparing PDF files online has some popular advantages:
- No software installation required
- Independence from the operating system and computer performance
- Results can be achieved quickly
- Easy to learn operation
- You can share comparison results (URL for distribution)
Before comparing PDF documents online, however, you should also consider the associated disadvantages:
- Your confidential documents are transmitted over the Internet, processed and stored on third-party computers – in some cases under foreign law
- The comparison results may also be published under certain circumstances
- Insufficient browser compatibility can lead to a different display or different operating behavior than intended by the software developer
- Versions of the software can be changed without your knowledge and lead to different results
- Longer upload and download times depending on the file size and throughput of the Internet connection
- Limitations in performance and availability compared to a local installation
- Limited interaction possibilities of the GUI
- Limited configuration options and possibly no storage of your own settings
Above all, check the first point:
Do you want to compare confidential documents online?
These include in particular:
- Personal data, which is covered by legal data protection under the GDPR
- Business secrets
- Financial data
- Even published documents which can be confidential up to the date of publication (business reports, research results)
How confidential are your documents? Just do a quick test to find out.
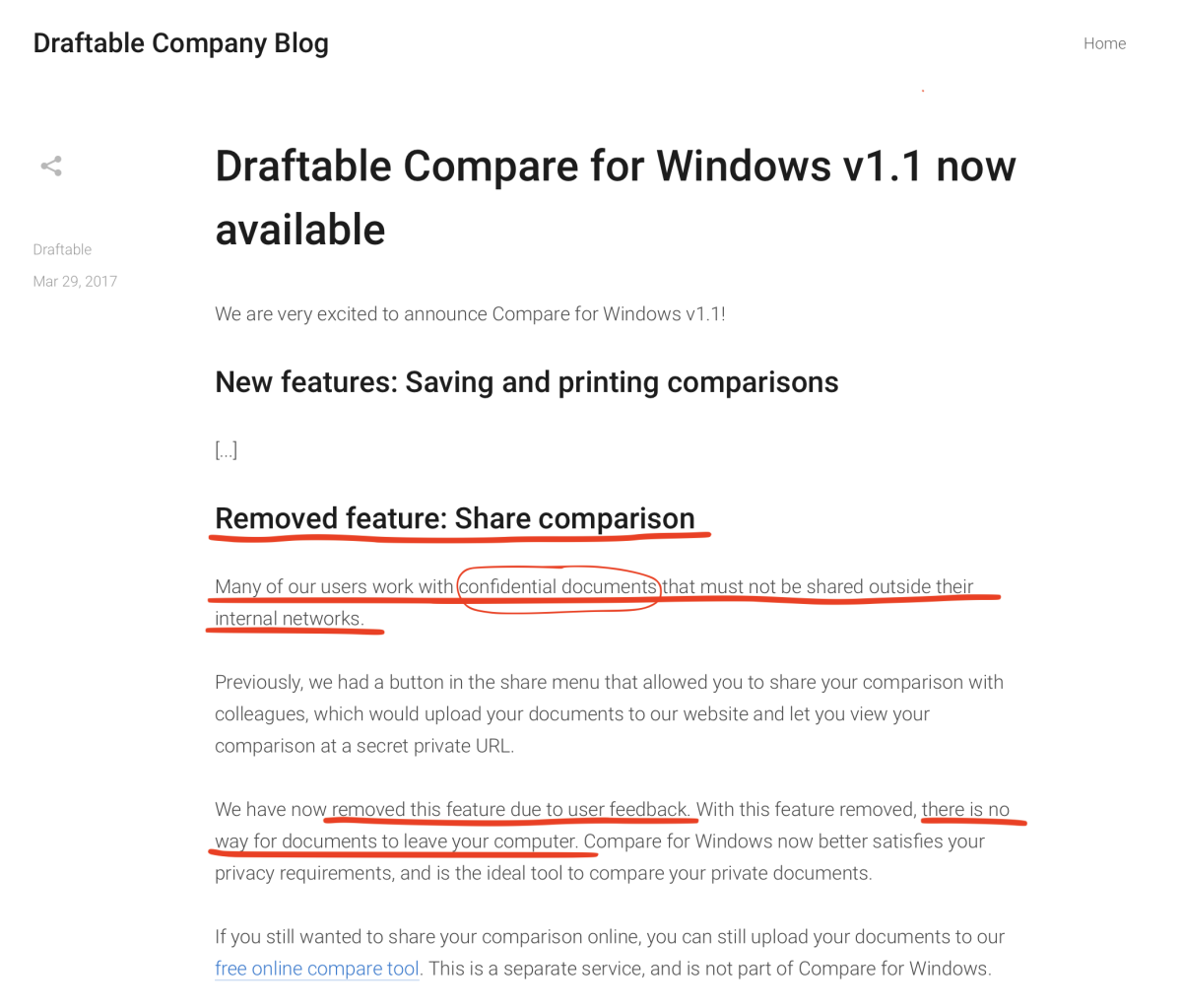
How important is the protection of your confidential documents to other users? This Draftable Compare announcement makes it clear:
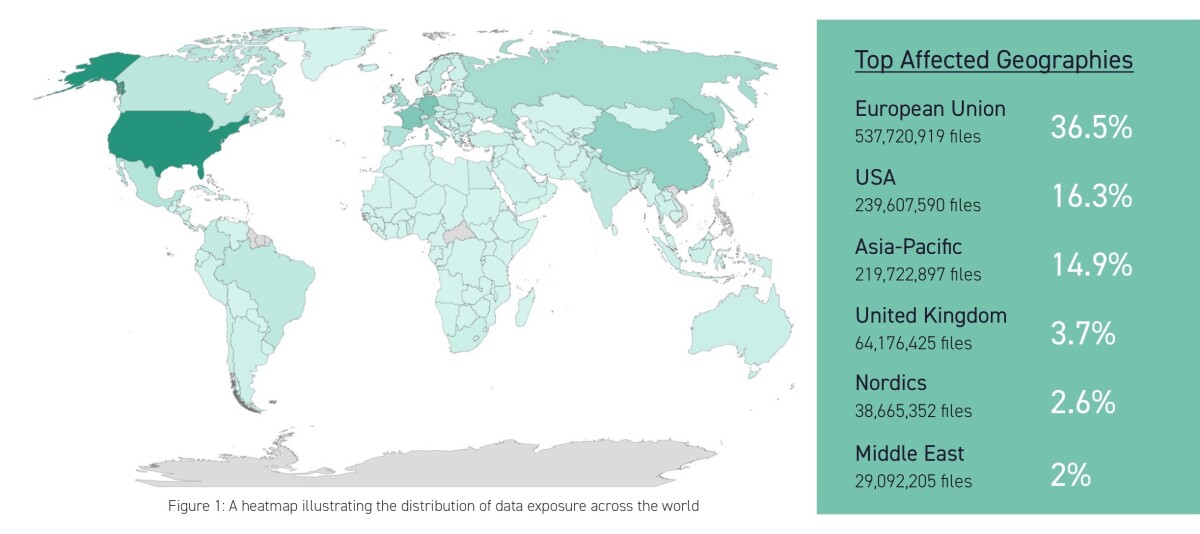
And how often does it happen that confidential documents appear on the Internet? There is also a current study by the security company Digital Shadows. According to this, 12,000TB of data from confidential documents were found in 1.5 billion files without access protection on the Internet:
Tip 3: Find out which PDF technology is used by your compare tool!
Whatever tool you want to use to compare PDF documents, what is the most important factor for optimal results? In short: the quality of your comparison results depends on the PDF technology that is built into the software!
Why is that so? Because the very first step of any comparison software is basically (see Tip 1):
- to render a pixel image of your PDF (for a graphical comparison)
or
- to extract the readable text from the PDF (for a text comparison)
Both are easier said than done. Since PDF is such a complex format, both of these steps are not an easy task, even for professionals. Therefore, no comparison software on the market will have its own implementation, but always use an existing PDF library for rendering and extracting text.
Find out which PDF library is built into your software! This allows you to assess whether your results match your requirements. Without the right foundation, you would otherwise have built on sand, no matter how beautiful the GUI or the reports look – no matter what the performance or price of the software is.
A short list of PDF libraries can be found on Wikipedia. An overview of PDF libraries on mobile platforms can be found at Toughdev.
The challenge of rendering PDF
A study of the company Alfresco compares eight current PDF libraries on their rendering results. Accordingly, every PDF library provides different results when rendering. Here is an example of the display of rendered text:

The differences are even stronger when rendering graphics – on the left a test PDF in Adobe Acrobat Reader, on the right the same PDF in Foxit Reader:
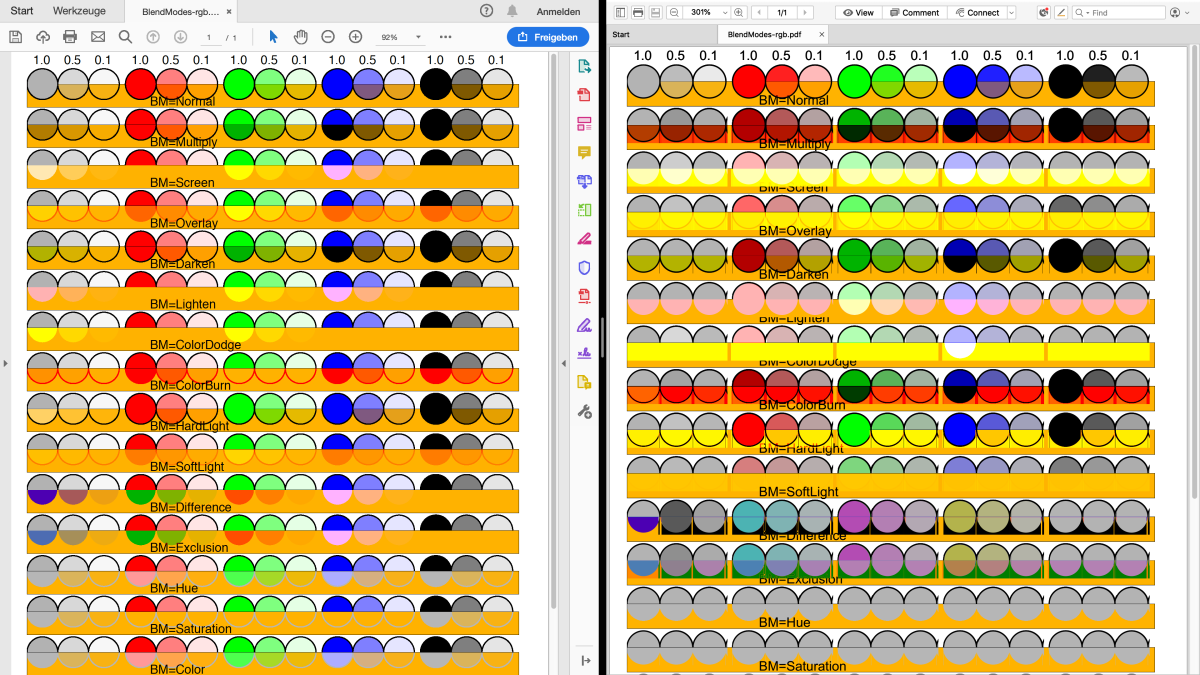
| Adobe Acrobat Reader | Foxit Reader |
The challenge of extracting text from PDF
The task of extracting text from PDF files is also not trivial.
In a paper, Bast & Korzen compare the text extraction of 14 different PDF libraries. Also interesting is the list of possible problems found while extracting text from PDF files:
- Spurious linebreaks
- Missing linebreaks
- Spurious paragraphs
- Missing paragraphs
- Reordered paragraphs
- Spurious words
- Missing words
- Misspelled words
Further challenges in text extraction can be found in a list by the producer of the PDFlib TET:
- Merging of hyphenated words (dehyphenation)
- Artificial boldface through shadows
- Diacritical marks (accent marks)
- Ligatures
- Drop caps (large initial characters)
- Unicode mappings
- Bidirectional text (e.g. Arabic, Hebrew)
- Damaged PDF documents
The market leader
The market leader in both areas is the Adobe PDF Library from the inventor of the PDF format. The results of Adobe products serve as a reference in cases where there are ambiguous interpretations of the PDF standard: What Adobe displays during rendering or extracts as text is then used as a reference. No matter what all other tools or libraries deliver instead.
This is also the problem with all of the above-mentioned benchmarks and comparisons, which incidentally often do not even include commercial products as candidates in the evaluation. Mostly for cost reasons, often also for licensing aspects (virality of the GNU General Public License).
![]() No question about it, the Adobe PDF Library costs good money.
No question about it, the Adobe PDF Library costs good money.
And therefore you will not find it in any freeware, any low-priced software and only in very few online portals.
However, if you cannot do without reliable graphical results or a reference for text extraction, then there is no getting around the Adobe PDF Library. And the acquisition costs will pay off quickly.
When can you switch to an alternative PDF engine?
Here is a small checklist:
- No requirement for display according to reference representation (absolutely necessary for prepress and printing!)
- PDFs do not contain any complex graphic elements (overprint, transparencies, special color spaces)
- The PDFs are completely homogeneous: generated with the same PDF software (also identical version!), with uniform settings, with similar content and identical fonts
- Your PDFs are not distributed to heterogeneous environments, where they are viewed, processed or printed with different PDF viewers or uncontrollable viewer settings
- Text extraction does not require high levels of detail in relation to the original text (e.g. search engine indexing tasks)
Interestingly, these are all points that contradict the intention that PDF is used as an exchange format with a stable cross-platform representation.
Tip 4: Check if you can avoid scans as input!
Many users think: “If I have a document on paper, I can just scan it and save it as a PDF. Then, I can compare this PDF directly with another PDF.”
Unfortunately, this assumption is wrong! Experience has shown that users will be so dissatisfied with the comparison results that they are very likely to give up the topic of document comparison in frustration. Why is that so?
What is so problematic about scans?
Put simply, it is because two worlds collide here: the wild analog world (paper) is beamed into the precisely straightened digital world.

Born-digital PDF

PDF of a scan
Technically speaking, scans are an A/D conversion. And even if the result of the conversion is a digital image, as a remnant from the analog world it contains numerous serious differences to the digital original:
- Color deviations due to the intrinsic color of the paper, color differences when creating the print and recording properties of the image sensor
- Inaccurate geometry due to misaligned paper placement or non-planar paper
- Marginal effects such as shadows and missing or deformed outer edges
- Translucency from the back with double-sided printing
- Moiré effects from printing screens or surface structures
- Blur
- Reflections on glossy surfaces, underexposure in dark areas, overexposure or poor contrasts, uneven lighting over the page area
- Distorted geometries due to uneven movement of the scanning mechanism or the paper feed
- Compression artifacts through lossy compression methods (JPEG)
- Deviations due to creases, staples, holes and handwritten notes
- Dirt on the scanner, particles in the paper, unclean printing
And there is another important difference that every scan has compared to the digital original: The result of the scanning process is a digital image, even if you save it as a PDF:
- A scan is initially just a pixel image. In particular, the PDF therefore contains no vector graphics and no searchable text.
What do I have to consider when comparing scans against PDF?
There are basically two options here (see tip 1):
- If you want to check a scan with a text comparison against a PDF, you must have searchable text added to the scan image with an OCR software. Even with the best text recognition software, you will get some incorrectly recognized letters. With a recognition rate of 99.9%, this is still an error approximately every 150 words – in the best case. In practice, the result will be worse for poor scan originals.
- If you want to check the scan against a PDF with a graphical comparison, the comparison software must compensate for all systematic image deviations described above. That is, before any meaningful comparison results can be determined, you need image processing functions for geometry correction, color adjustments, noise and error suppression. All these features can only be found in comparison software for the professional sector. Often, special expertise is also required to optimally generate the scans and to configure the compensation algorithms correctly. In principle, even for well-calibrated systems, you will find significantly more differences than would ever be acceptable with a comparison between digital documents.
Hence our well-intentioned advice: Whenever possible, you should avoid scans as inputs and compare the digital documents!
Remember: Almost every document you hold on paper was previously created on a computer! Make sure you try to get to these digital documents and you will make a quantum leap in the quality of your comparison results!
Tip 5: Optimize the quality of your inputs before tampering with comparison results.
Do you know the phrase Garbage In, Garbage Out?
This truism is especially true for comparing PDFs: If you work with bad inputs, you cannot generate good outputs either.
Conversely, if you are not satisfied with the comparison results, the first and most important remedy should be: Optimize the quality of your inputs.
Here are a few immediate actions that will help you:
Generate your PDF export correctly
You have your documents or artworks created with Word, InDesign, Illustrator or ArtPro. What is the best way to create a PDF?
The answer is actually quite simple:
- Use the function Export as PDF or Save as PDF directly from the native software with which you created the document.
This is the safest way to create an optimal PDF from your documents, with the best possible internal structure of the PDF content.
Nowadays, every software has such a function for PDF export. If not, you should check whether you really have a current version installed. (If your software does not actually have a PDF export, it is probably high time to switch to another contemporary DTP program.)
Some very problematic ways to generate PDF are:
- PDF printer driver: a virtual printer that you access from your software with the Print function to generate PDF documents (e.g. PDFCreator or numerous other PDF printers)
- Adobe Distiller: generates PDF by going through PostScript
Although the PDFs generated in this way may look good for a human viewer, the internal technical structure can be completely mixed up from the point of view of a PDF comparison software.
For a text-based PDF comparison, the word order in PDFs generated in this way is often incorrect and no longer matches the original logic of the document. Special fonts, accent characters and symbol characters can also be lost by the trick with the PDF printer if they are embedded as graphic elements instead of text.
And for a graphical PDF comparison, where you want to compare artworks or graphically sophisticated documents, such an indirect export is prohibited anyway. Because for laboriously created subtleties – such as overprint properties, transparency and precisely positioned graphic elements – 100% correctness cannot under any circumstances be guaranteed with this detour.
Avoid PDF tools for subsequent editing of the PDF
Tools for editing PDF are very popular. Before you apply such tools to your PDF files, please keep in mind: Modifications to PDFs are always prone to errors.
These include the following changes to PDFs, which you should avoid as much as possible:
- Remove pages from the PDF
- Merge multiple PDF files into one PDF
- Delete or blacken PDF text or objects
- Compress PDF to reduce the file size
- Crop areas in the PDF
- Hide spot colors or PDF layers
- Changes to the PDF boxes (MediaBox, CropBox, TrimBox, BleedBox, ArtBox)
It is better to follow this rule:
Always use your original PDFs as input for the PDF comparison. And let the operations from the above-mentioned list be performed directly by functions in the PDF comparison software.
This way, you avoid the risk of incorrect modifications by PDF tools.
Optimize OCR results for scans
If you absolutely have to work with scans (arguments against it, see Tip 4), you should do everything possible to optimize your OCR results.
Important points to consider:
- High-quality scanner for good scan results (including reliable paper handling)
- Powerful OCR software (free OCR software supplied with scanner drivers often delivers below-average results)
- Correct language settings for the OCR software (often an English dictionary is the default setting and must be changed to your local language)
- Optimized scan settings (resolution at least 300dpi, avoid JPG)
- Clean paper handling (smooth, white paper, good print quality, avoid stitching and handwritten notes/stamps)
Further tips can also be found, for example, in this study: 10 Ways to Improve Capture OCR and Indexing. There is also a useful conclusion:
What’s surprising is that the actual recognition phase of capture may seem to be the most important step relevant to automated indexing – since it is, after all, the phase where OCR is performed. But you’ll notice that at least half of the factors relevant to successful indexing occur during the pre-recognition steps, particularly in obtaining appropriate image quality for OCR and indexing.
Tip 6: Reduce displayed differences to a minimum!
So far, so good. You have followed Tip 1 to Tip 5 and now finally come to take a closer look at the comparison results for your PDF files.
You will be surprised! Because a digital PDF comparison will give you a completely different result than you know from the manual comparison:
In principle, you will see a lot more differences than expected.
Isn’t it really nice, how exactly the differences are highlighted down to the smallest detail? Yes – and no!
Because a new problem arises very quickly: If you see too many differences, you risk again that important differences are drowned out in the mass of unimportant differences.
Then you reach the point that even the most beautiful precision of the digital PDF comparison is of no use anymore because you cannot see the wood for the trees.
Therefore, our important tip how to get most out of the comparison results:
Less is more! Always try to reduce the number of displayed differences to a minimum.
To do this, use the settings and tools (examples see below) of your PDF comparison software to filter out non-relevant differences.
This way, you avoid the risk of overlooking really important differences in a mass of unimportant differences.
A few examples of settings and tools to reduce unimportant differences:
- In a graphical PDF comparison:
- Definition of an ROI (region of interest) to exclude uncritical areas from the comparison (e.g. the legend or, in the case of folding boxes, the area outside the dieline)
- Hiding of spot colors or layers to exclude technical elements (dimensions, crop marks, varnish-free zones)
- Adjustable tolerances to ignore smaller color deviations and tiny pixel differences
- Grouping of delta pixels into larger difference regions instead of displaying each pixel separately
- In a text-based PDF comparison::
- Exclusion of individual pages (e.g. front matter or appendices) in order to limit the comparison to the main text
- Definition of exclusion areas (e.g. headers and footers) in order to hide frequently changed page areas
- Handling of word hyphenations (dehyphenation) in order to be able to ignore changed line breaks
- Replace function to uniformly adjust systematic word changes between the two versions
- Adjust the text flow to synchronize complex layouts despite internally changed word order
Tip 7: Work interactively with the comparison results: inspect, review, comment… No sweet without sweat!
Let’s say you have managed to reduce your computed comparison results to the achievable minimum with the help of Tip 6. What’s next? Is your work done now? Unfortunately, it’s not.
Now comes the most important task of all:
The evaluation of the displayed differences. Your expertise and your decision on how to rate the individual differences and how to proceed with them are required here.
This work step consists of the evaluation triad:
|
|
|
|
| 1 | 2 | 3 |
For each single difference displayed, the following typical questions must be answered:
 Inspect
Inspect
- What exactly is the difference between version A and version B?
-
Your comparison software should give you a list of differences that you can step through from one difference to another.
- Your comparison software has no navigable list of differences at all? This means: You get differences, but have to search for them yourself? The risk of overlooking individual sites is thus growing considerably. This restricts the benefits of the software so severely that you should seriously consider switching to another solution.
-
For the current difference, the software should show you a clear comparison of what the site looks like in version A and version B.
-
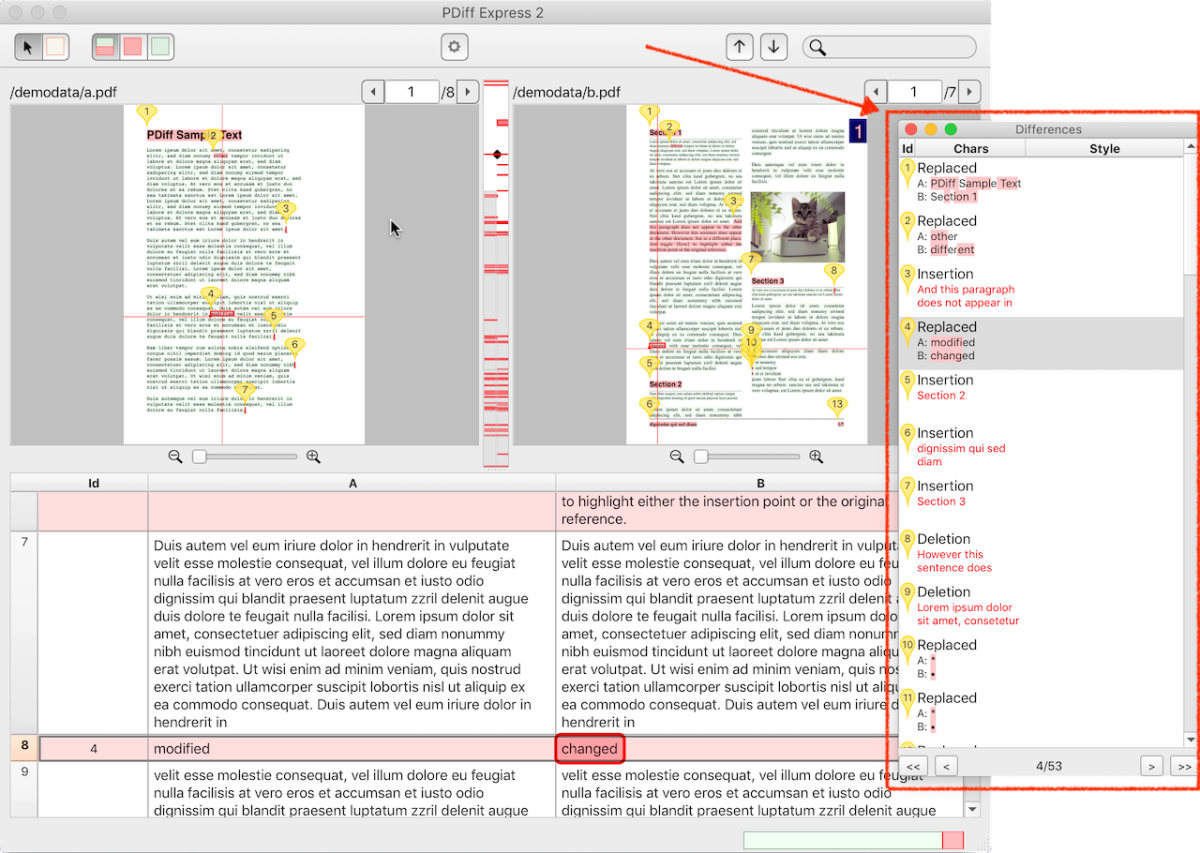
List of differences – text-based comparison: for example with PDiff
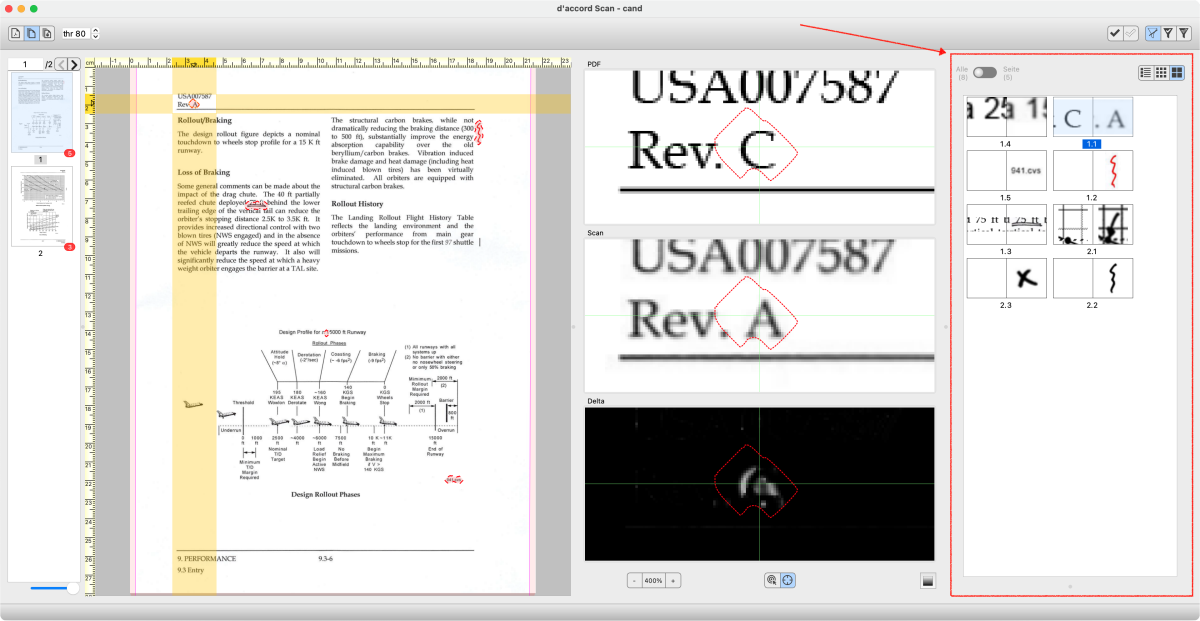
List of differences – graphical comparsion: for example with d’accord Scan
Inspect: graphical comparison
In the case of a graphical comparison, additional inspector tools such as a zoom function will help you to identify details and delta pixels more precisely. A blinking function where the display quickly toggles between version A and B is also very helpful in order to be able to understand the differences at a glance.

Inspect – graphical comparison: for example with d’accord
Inspect: text-based comparison
For a text-based comparison, it is important to have inspector tools that show you the actually extracted text with details on fonts and font attributes (bold, italic, superscript/subscript, underline and strikethrough).The mapping of characters to Unicodes and a character-by-character diff (as a supplement to the word-by-word diff) also help you to understand differences that are visually difficult to recognize.
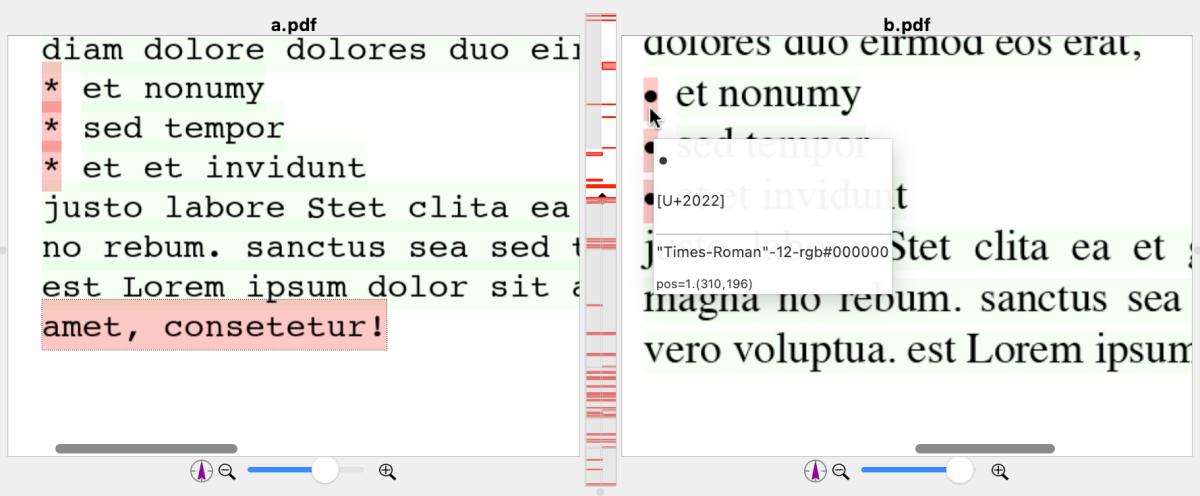
Inspect – text-based comparison: for example with PDiff
 Review
Review
- Is it a really relevant difference or is it a negligible difference
or an artifact (false positive)?
- As a rule, the machine-based comparison will be significantly more sensitive than a human viewer. Therefore, the software should offer you the opportunity to hide negligible differences individually (for example, by a checkbox to tick off).
- Is it an intended change or an unintentional change? What made the
difference?
- The key question that only you can answer and no software:
- Is the change okay and is it accepted by you?
- Or is it an unintentional change (e.g. editing at one place in the document has inadvertently affected a completely different place or a bug in the DTP software has caused an unwanted change)…
- … or is it an undesirable change (e.g., in a contract, the other party has changed a text passage to your disadvantage)
- You must be able to make this decision “accepted” vs. “rejected” for each individual change and be able to document it with the comparison software. Ideally with selectable categories or free-text comments.
- The key question that only you can answer and no software:
- Have all intended changes (corrections) actually been made in the
new version?
- Often there is also the opposite case: The absence of a difference is rated as an error. If you check a list of corrections, then you expect an intended change to exist in version B.
 Assess
Assess
- How do you deal with the differences?
- If found differences need to be corrected, you should be able to mark them accordingly. Common tools are here again the above-mentioned check off function, selectable categories or comments.
- The normal case will be that you are satisfied with all the differences found. Even then, it can make sense to explain the individual differences to other users of the document (e.g. customers, colleagues, regulatory authorities) in more detail. For this you can also use the functions check off, selectable categories or comments.
- Ultimately, as an overall result, your decision on the acceptance of the new version is pending: Is the new version B okay based on the differences found? Or does a single change completely invalidite the entire new version B of the document? This decision should also be documentable. Usually even a paper report and your signature are required for this (see Tip 8).
Tip 8: Only outputs fitting your needs are good outputs!
Software for PDF comparison usually also offers the option of generating a comparison report as output. Well and good.
But before you settle for the first (in the worst case even only possible) output, you should first think carefully about what kind of output you ideally want.
And then in the second step, you check how your comparison software can be configured to produce the output that is optimally adapted to your requirements.
- Your comparison software has several output formats and the reports are even configurable in form and content? Then, you are on the safe side that you can generate the optimal output for your target group. And you are also well equipped for possible future applications.
- You can only generate one output format and not further configure the form and content? Then, check carefully whether the output can meet your requirements and suit your target group. Otherwise, you should consider another solution.
Depending on who your target group is, the optimal output can look very different:
For customers
- Goal: clarity, comprehensibility, efficient usability
Your customers want to get an overview of the differences in the two versions as quickly as possible. You may even offer the comparison report as an additional service. It is precisely then that the additional benefit comes first.
You would rather spare your customers too many details. After all, the added value should not have any disadvantages for you in the form of misunderstandings or increased queries.
A PDF report, which should be as clear and self-explanatory as possible, is ideal as an exchange format. For example, a quick comparison of version A + B (side-by side) with highlighted differences. If the differences are also marked as PDF comments, they can be viewed in free PDF readers as a navigable list and, if necessary, also contain your comments on the individual differences.

|
| PDF report version A+B |
For colleagues
- Goal: completeness, traceability, reproducibility
Unlike your customers, your colleagues would rather be supplied with a very detailed and reproducible output.
A PDF report, which clearly shows all the differences, including your ratings and comments, is certainly helpful for quick communication. However, it should also contain as many details as possible on how you came to the result: file paths of the input documents used (for clear identification, preferably including MD5 checksums), the program settings used, the work steps you carried out, etc.
If you want to save a hundred percent reproducible comparison result as output for yourself or your colleagues, a PDF report is not the best choice. Instead, your software should also be able to save its own project format. This makes it easy to load and edit a comparison. For example, you can add more comments or perform a recalculation with improved comparison parameters.
It often happens that you have created a new version C of the document as a revision of version B and now want to compare it with the original version A. Here, too, it is easiest to load the saved project with the comparison A vs. B and replace the previously compared version B with the new version C.
|

|
| Detailed PDF report | Own project format |
For regulatory authorities or quality assurance
- Goal: Compliance with formal requirements
If you want to use your comparison reports for quality assurance – especially in highly regulated industries (e.g. pharmaceuticals, medical devices, food or energy) – your outputs must meet special formal requirements.
A PDF report is also suitable as an exchange format here. The content should of course contain clearly understandable differences between the document versions.
Depending on the industry, there may be special formal requirements for this: For example, in the case of medical regulatory authorities and in the legal field, it is necessary to indicate the comparison result as a synoptic comparison of the texts in which the corresponding passages are depicted at the same height and the complete text from both documents is visible.
In addition, the report should also contain all the details in the sense of an audit trail, such as:
- User
- Time stamp
- Settings used/Software version
- Steps taken to ensure reproducibility of the result
- Reason for the change
- Signature (handwritten or electronic)

|
| Tabular PDF report with text synopsis |
For automation
- Goal: Machine readability
If you want to process your comparison result automatically, e.g. in your own software systems or complete workflow solutions, then a PDF report will not be useful.
What you need is a machine-readable output, such as in XML format or CSV format. In the simplest case, a plain return code is sufficient, which shows whether the comparison found differences or whether both documents with the current settings are considered as identical.

|

|
| XML / CSV | Return-Code |
Tip 9: The more you standardize and automate, the better!
If you compare PDF documents frequently, you will quickly find out how to get the best results. The best way to retain this knowledge for yourself (and your colleagues) is to standardize the comparison process:
In the simplest case, these can be some work steps or settings. In the maximum case, also a complete automation.
Advantages of a standardized comparison process
- Consistent quality across different documents, times and users
- Efficient knowledge management (optimum settings and procedures)
- Increased user acceptance (because it becomes easier to achieve the desired result) and higher proportion of checked documents
- More throughput of checked documents
- Cost and time savings
What can be standardized?
Input data
Do you create your own documents? Then, you can standardize many things already during the creation of the documents, which is helpful later for the PDF comparison (see also Tip 5). For example:
- Content and structure of the documents, e.g. styles with Unicode-compatible fonts, use of PDF layers for technical objects such as dieline and varnish-free zones, if necessary uniform naming scheme for spot colors of technical objects
- Export method for saving in PDF format
- File names and locations for mapping the two PDFs to be compared
- If you work with scans, optimize the settings in your scanning process (see also Tip 4).
With externally generated documents, standardization becomes more difficult, but not impossible.
- Are there certain documents with better comparison results than the other inputs? Can you find out why this could be (e.g. different software for PDF generation, problematic fonts, complex graphical properties of objects or different settings during export)? Contact your supplier and ask for their help.
- If you are a client for the document generation, then you can even set specifications with your supplier on the structure and format of the documents, which make it much easier or even make it possible for you to use the documents for PDF comparison.
- Or classify sources based on your experience so that you know at an early stage where more problematic or unproblematic documents come from and how you can calculate your workload according to the source.
Processing
For the actual comparison process, there are different approaches to standardize the process:
Save settings that have proven to be good in order to use them again for further comparison projects. Some examples of typical settings:
- Render settings
- Tolerance thresholds
- PDF boxes (MediaBox, CropBox, TrimBox, …), exclusion areas or ROI
- Default names of layers/spot colors with technical objects
Ideally, you can even save several setting profiles with your software and then reuse them according to the respective use case (e.g. depending on the type of input data, certain customers or your internal project type).
For the exchange with colleagues or between different computers, it is very helpful if the settings profiles can be exported to a file. You can then exchange them department-wide (by a shared network drive or e-mail).
In addition to setting profiles, you can also define the working steps for the PDF comparison in a kind of guide:
- Steps to minimize the differences (Which differences are reduced with which functions?)
- What can/should be hidden and what not?
- How is the procedure documented?
You can also define standardized processes for the assessment:
- Inspect (Does every difference have to be marked as “seen”?)
- Review (Does every difference have to be commented on? Definition of categories or standard formulations for the comments.)
- Assess (When should the entire document be accepted or rejected?)
Output data and post-processing
Finally, the outputs and the post-processing of the outputs can also be standardized - such as:
- Definition of the appropriate report format
- Scope and layout of the report as part of the settings
- File names and locations to document the comparison result
- Further procedures after acceptance or rejection
What can be automated?
You get the highest degree of standardization through a complete automation of the document comparison. Typical solutions for this are:
- Batch operation in the GUI
- Batch operation via CLI
- Call from your own scripts
- Call from complex software systems
- Hot folder technology
- Integration into workflow systems
Typically, automation will split your documents into two classes:
- Unproblematic documents that can be processed directly.
- Conspicuous documents that should be reviewed again manually.
Some of the conspicuous documents can then be assigned to class 1 for further processing. The rest requires further revision and will be re-entered into the test system as a revised version.
Tip 10 (pro tip): Check your workflow!
Of course, we are happy about the positive feedback from our customers, who tell us how using our PDF comparison software has helped them to compare their documents faster and more reliably. How they have integrated the processes into their quality assurance and how they can now clearly document the test results.
But apart from the many technical details that we have dealt with here, there is a surprising insight from some particularly satisfied customers:
In addition to the direct benefit of PDF comparison software, the standardization and automation introduced (see Tip 9) have resulted in a far greater advantage. As a positive side effect, these customers have particularly benefited from the fact that they have carried out a re-evaluation and advancement of their entire work processes with regard to the creation and further processing of documents.
Some ideas what you could check in your workflow:
- Where do you find different document versions in your company? Are the versions already being reliably compared with one another?
- Are the versions created by you and can they be further standardized?
- Or do you get one/both versions from external sources and can already improve the quality there?
- Are all test results sufficiently documented and what are the processes for further processing?
- It may make sense to perform version comparisons for several intermediate steps of the processing chain - and not only between very different versions from far away processing steps. In general, the layout at the beginning of the processing chain changes greatly. Towards the end, it should be more and more stable. Then software solutions with different comparison approaches may be necessary (see Tip 1).
- Take your suppliers and customers on board by providing them with comparison reports. Both groups will be grateful for objective results and appreciate the quality of your work.
Use case: Automated PDF Comparison in CI/CD Pipelines
In many applications, PDFs are generated automatically, for example reports, invoices, or technical documentation. Therefore, it can be useful to integrate PDF comparison directly into CI/CD pipelines3.
Typical use cases include regression testing for PDF reports, build pipelines for automatically generated documentation, or QA automation. In these scenarios, a newly generated PDF is automatically compared with a reference version to detect unexpected changes at an early stage.
For such workflows, a comparison tool should provide a command-line interface (CLI) and output results in machine-readable formats such as XML. Using exit codes, the pipeline can automatically determine whether differences were found and react accordingly.
-
As always: Exceptions prove the rule. In fact, there are a few special solutions that have recently taken a hybrid approach: The PDF is first separated into text and non-text (the rest like pixel graphics and vector graphics) Then a text comparison and a graphical comparison are applied separately. All of the above statements about the individual comparison methods still remain valid for the respective content type. An example of a hybrid approach is our Diff GT. ↩
-
With OCR software you can convert the text back into searchable text with some restrictions. You can find an overview of the recognition performance of current OCR solutions in the article OCR in 2023: Benchmarking Text Extraction/Capture Accuracy. See also Tip 4. ↩
-
CI – Continuous Integration: In Continuous Integration, code changes are regularly integrated into a shared repository.
CD – Continuous Delivery / Continuous Deployment: CD extends CI by adding the automated release process. ↩